|
Fully Automated Subject Access Before beginning to review that knowledge, we must first address a prior issue. Many people in our society, including many in the Internet and digital resources environments, assume that subject access to digital resources is a problem that has been solved, or is about to be solved, with a few more small modifications of current full-text indexing systems. Therefore, why worry about the various factors addressed in this article? There are at least two reasons. First, the human, domain, and other factors would still operate in a fully automated environment, and need to be dealt with to optimize the effectiveness of information retrieval (IR) systems. Whatever information systems we develop, human beings still will come in the same basic model; products of human activity, such as databases, still will have the same statistical properties, and so on. As should become evident, failure to work with these factors will almost certainly diminish the resulting product. Second, it may take longer than we think to develop fully automated systems. At conferences, researchers present their new system and say, "We are 70 percent there with our prototype system. Just a little more work, and we will have it solved." This happens because, indeed, it is not difficult to get that first 70 percent in retrieval systems--especially with small prototype systems. The last 30 percent, however, is infinitely more difficult. Researchers have been making the latter discovery as well for at least the last thirty years. (Many of the retrieval formulas that have recently been tried were first used in the 1950’s and 1960’s. See, e.g., Luhn, 1957; Stevens, 1965.) Information retrieval (IR) has looked deceptively simple to generations of newcomers to the field. But IR involves language and cognitive processing and is therefore as difficult to automate as language translation and other language processes based on real-world knowledge, which researchers have been trying to automate virtually since the invention of the computer. Information retrieval also poses serious scalability problems; small prototype systems are often not like their larger cousins. Further, user needs vary not just from one time to another, but from one subject domain to another. Optimal indexing and retrieval mechanisms may vary substantially from field to field. We can do an enormous number of powerful things with computers, but effective completely automated indexing and access to textual and text-linked databases eludes us still, just as 100 percent perfect automatic translation does, among other things. Meanwhile, a lot of other IR capabilities go undeveloped, in deference to the collective assumption that we will soon find a way to make it possible for computers to do everything needed in information retrieval. The human side of the IR process needs attention too. The really sophisticated use of computers will require designs shaped much more in relation to how human minds and information needs actually function, not to how formal, analytical models might assume they do. Attention to these points will be productive for effective IR, no matter how soon, or whether, we find a way to develop good, fully automated, IR.
Human Factors Subject Searching vs. Indexing It is commonly assumed that indexing and searching are mirror images of each other. In indexing, the contents are described or represented, or, in full-text searching, indicative words or phrases are matched or otherwise identified. On the searching side, the user formulates a statement of the query. Then these two representations, of document and of query, are matched to retrieve the results. But, in fact, this is only superficially a symmetrical relationship. The user’s experience is phenomenologically different from the indexer’s experience. The user’s task is to describe something that, by definition, he or she does not know (cf. Belkin, 1982). (Knowledge specifically of what is wanted would lead to a "known-item" search.) The user, in effect, describes the fringes of a gap in knowledge, and can only guess what the "filler" for the gap would look like. Or, the user describes a broader, more general topic area than the specific question of interest, and says, in effect, "Get me some stuff that falls in this general area and I’ll pick what looks good to me." Usually, the user has no tools available to help with that problem of describing the fringes of the gap, or the broader subject area. In many cases, the problem for the user is even more difficult than indicated above. In years of studies, Kuhlthau (1993) has documented that the very process of coming to know what one wants in the first place is seldom straightforward. In a search of any complexity, as for a student term paper, one does not so much "pick a topic," as is usually assumed, but rather discovers, develops, and shapes it over time through exploration in materials in an area of interest. One may use an information system at any point in this gradually developing process. The need may evolve and shift at each stage of developing knowledge of the subject. (See also my own model of the evolving and changing information need--Bates, 1989a. ) Use of an information system early in a project will naturally come out of a much less well specified and articulated information need--yet the searcher must nonetheless find a way to get the information system to respond helpfully. The indexer, on the other hand, has the record in hand. It is all there in front of him or her. There is no gap. Here, ideally, the challenge for the indexer is to try to anticipate what terms people with information gaps of various descriptions might search for in those cases where the record in hand would, in fact, go part way in satisfying the user’s information need. This can be seen to be a very peculiar challenge, when one thinks about it. What kinds of information needs would people have that might lead them to want some information that this record would, in fact, provide? As Harter (1992) points out, discovering that a particular article is relevant to one’s concerns, and therefore a good find, does not necessarily mean that the article is "about" the same subject as one’s originating interest. As he notes, regarding his own article on the concept of psychological relevance:
...the present article [on psychological relevance] may be found relevant, by some readers, to the topics of designing and evaluating information retrieval systems, and to bibliometrics; I hope that it will. However, this article is not about these topics. (p. 603, emphasis in the original) Conceivably, infinitely many queries could be satisfied by the record in hand. Imagining even the more likely ones is a major challenge. (See extensive discussions in Wilson, 1968; Soergel, 1985; Green & Bean, 1995; Ellis, 1996; and O’Connor, 1996.) But in fact, historically, and often still today, catalogers and indexers do not index on the basis of these infinitely many possible anticipated needs. Instead, and perhaps much more practically, they simply index what is in the record. (See also discussion in Fidel, 1994.) In other words, they attempt to provide the most careful and accurate possible description or representation of the contents of the record. This situation differs in many ways from the phenomenological circumstances of the user. We should not be surprised, then, if the user and the indexer use different terminology to describe the record, or, more generally, conceptualize the nature and character of the record differently. For the indexer, there is no mystery. The record is known, visible before him or her. Factual information can be checked, directly and immediately, to create an absolutely accurate record. The user, on the other hand, is seeking something unknown, about which only guesses can be made. What happens in retrieval if the searcher’s guesses have little (or big) inaccuracies in them, and do not match the precise and accurate description provided by the indexer? Further, the indexer is experienced with the indexing system and vocabulary. Over the years, with any given system, fine distinctions are worked out regarding when one term is to be used and when another for two closely related concepts. Indexers create rules to cover these debatable situations. Eventually, mastery of these rules of application comes to constitute a substantial body of expertise in itself. For example, the subject cataloging manual for the Library of Congress Subject Headings (Library of Congress, 1996) runs to two volumes and hundreds of pages (Library of Congress, 1991- ). This manual is not the same as the subject heading listings. It does not consist so much of general indexing principles as it does of rules for applying individual headings or types of headings. For example, under the subject "Strikes and Lockouts," section H2100 of the manual, four pages of instructions are given for creating headings for strikes in individual industries and for individually-named strikes of various types. Thesaural indexing systems also frequently have "scope notes" that tell the indexer how to decide which term to use under debatable circumstances. Often, these rules are not available to searchers, but even when they are, the naive searcher--and that includes Ph.D.’s, as long as they are naive about indexing--will usually not realize there are any ambiguities or problems with a term, and will not feel a need to check it. The user has in mind the sense of a term that interests him or her, not the other senses that the indexer is aware of. Only upon retrieving false drops will the user realize there is even any problem. In short, the user almost always knows less about the indexing issues in a topic area than the indexer does. The user approaches the system with an information need that may be formulated out the of the first words that come to mind (See Markey, 1984b, on the many queries she found that "could be categorized as ‘whatever popped into the searcher’s mind.’" p. 70). Consequently, the user’s input is liable not to be a good match with the indexer’s labeling, which is derived from years of experience and analysis. The indexer, on the other hand, cannot undo his/her far greater knowledge of the indexing issues. After indexers have been at work for one day, or attended one training session, they know more, and have thought more, about indexing issues than even the most highly educated typical user has. Already, an expertise gap is forming between the user and the indexer that nearly guarantees some mismatches between user search terms and indexing terms on records. The same phenomenological gap will hold true for the match between the system user and bodies of data that have been automatically indexed by some algorithm as well. The creator of the algorithm has likewise thought more and experimented more with the retrieval effects of various algorithms than the typical user has, before selecting the particular algorithm made available in a given system. Yet, at the same time, the full statistical consequences of such algorithms can never be anticipated for every circumstance. Results achieved through such algorithms will seldom dovetail exactly with what humans would do in similar circumstances. So the result is a peculiar mix of expert human understanding of indexing with non-sentient statistical techniques to produce a result that is never just like interacting with another human would be. Again, we have a phenomenologically different experience for the researcher/designer on one side, and the user on the other. Further, no retrieval algorithm has been found to be anywhere near perfectly suitable (more on this later), yet the principles by which the algorithm is designed are seldom made fully available to end users--just as the indexing principles seldom are--so the user could try to find ways around inadequacies. Still another factor is likely to operate in the behavior of catalogers, indexers, and system designers for manual and automated systems. The information professional has an understandable desire to create, in an indexing vocabulary, classification system, or statistical algorithm, a beautiful edifice. He or she wants a system that is consistent in its internal structure, that is logical and rigorous, that can be defended among other professionals as well as meet all the usual expectations for creations of human endeavor. After years of working with problems of description, the creators of such systems have become aware of every problem area in the system, and have determinedly found some solution for each such problem. Therefore, the better developed the typical system, the more arcane its fine distinctions and rules are likely to be, and the less likely to match the unconsidered, inchoate attempts of the average user to find material of interest. This is by no means to suggest that IR systems should be inchoate or unconsidered! Instead, the question is a different one than is usually assumed. That question should not be: "How can we produce the most elegant, rigorous, complete system of indexing or classification?," but rather, "How can we produce a system whose front-end feels natural to and compatible with the searcher, and which, by whatever infinitely clever internal means we devise, helps the searcher find his or her way to the desired information?" Such clever internal means may include having distinct means of access and indexing. The two functions of indexing and access are not one and the same. It is not necessary to require the user to input the "right" indexing term, which the system in turn uses to search directly on record indexing. The design of the access component of a system can be different from the design of the indexing component, provided these two are appropriately linked. Thus, the user, with only vague, poorly thought through ideas initially of what is wanted, can be helped, with the right access mechanism, to find his or her way into the portions of the database that have been carefully and rigorously organized. It is unreasonable to demand of system users that they develop the expert indexer’s expertise. At the same time, it is unreasonable to demand of the indexers that they be sloppy and fail to note critical, and useful, distinctions. By developing an access mechanism--a user-friendly front-end--for the user, and linking it to the indexing, indexers can maintain standards, and users can benefit from the intellectual work that has gone into the system of description, without having to be experts themselves. (For further discussion, see Bates, 1986a, 1990.)
Multiple Terms of Access On this next matter there is a huge body of available research. Several people have written extensively about it (Furnas and others, 1983; Bates, 1986a, 1989b; Gomez, Lochbaum, & Landauer, 1990), and yet the results from these studies are so (apparently) counterintuitive that little has been done to act on this information in IR system design. It is as if, collectively, we just cannot believe, and, therefore do not act upon, this data. A few examples of these results will be described here; otherwise the reader is encouraged to explore the full range of available data on this matter in the above-cited references. In study after study, across a wide range of environments, it has been found that for any target topic people will use a very wide range of different terms, and no one of those terms will occur very frequently. These variants can be morphological (forest, forests), syntactic (forest management, management of forests) and semantic (forest, woods). One example result can be found in Saracevic & Kantor (1988). In a carefully designed and controlled study on real queries being searched online by experienced searchers, when search formulations by pairs of searchers for the identical query were compared, in only 1.5 percent of the 800 comparisons were the search formulations identical. In 56 percent of the comparisons the overlap in terms used was 25 percent or less; in 94 percent of the comparisons the overlap was 60 percent or less. (p. 204). In another study, by Lilley (1954), in which 340 library students were given books and asked to suggest subject headings for them, they produced an average of 62 different headings for each of the six test books. Most of Lilley’s examples were simple, the easiest being The Complete Dog Book, for which the correct heading was "Dogs." By my calculation, the most frequent term suggested by Lilley’s students averaged 29 percent of total mentions across the six books. Dozens of indexer consistency studies have also shown that even trained experts in indexing still produce a surprisingly wide array of terms within the context of indexing rules in a subject description system (Leonard, 1977; Markey, 1984a). See references for many other examples of this pattern in many different environments. To check out this pattern on the World Wide Web, a couple of small trial samples were run. The first topic, searched with the Infoseek search engine, is one of the best known topics in the social sciences, one that is generally described by an established set of terms: the effects of television violence on children. This query was searched on five different expressions that varied only minimally. The search was not varied at all by use of different search capabilities in Infoseek, such as quotation marks, brackets, or hyphens to change the searching algorithm. Only the words themselves were altered--slightly. (Change in word order alone did not alter retrievals.) These were the first five searches run:
violent TV children children television violence media violence children violent media children children TV violence As is standard, each search produced ten addresses and associated descriptions as the first response for the query, for a total of 50 responses. Each of these queries could easily have been input by a person interested in the identical topic. If each query yielded the same results, there would be only ten different entries--the same ten--across all five searches. Yet comparison of these hits found 23 different entries among the 50, and in varying order on the screen. For instance, the response labeled "Teen Violence: The Myths and the Realities," appeared as #1 for the query "violent media children" and #10 for "violent TV children." The search was then extended a little farther afield to a query on "mass media effects children." That query yielded nine new sites among the ten retrieved, for a total of 32 different sites--instead of the ten that might have been predicted--across the six searches. The previous example varied the search words in small, almost trivial ways. The variation could easily have been much greater, while still reflecting the same interests from the searcher. Let us suppose, for example, that someone interested in freedom of speech issues on the Internet enters this query: +"freedom of speech" +Internet This time the search was run on the Alta Vista search engine. The plus signs signal the system that the terms so marked must be present in the retrieved record and the quotation marks require the contained words to be found as a phrase, rather than as individual, possibly separated, words in the record. So, once again, we have a query that is about as straightforward as possible; both terms, as written above, must be present. Let us suppose, however, that three other people, interested in the very same topic, happen to think of it in just a little different way, and, using the identical system search capabilities, so that only the vocabulary differs, they enter, respectively: +"First Amendment" +Web +"free speech" +cyberspace +"intellectual freedom" +Net All four of these queries were run, in rapid succession, on Alta Vista. The first screen of 10 retrievals in each case was compared to the first 10 for the other 3 queries. The number of different addresses could vary from 10 (same set across all four queries) to 40 (completely different set of 10 retrievals for each of the four queries). Result: There were 40 different addresses altogether for the four queries. Not a single entry in any of the retrieved sets appeared in any of the other sets. Next, the search was expanded by combining the eight different terms in all the logical combinations, that is, each first term combined with each second term (free speech and Internet, free speech and Web, First Amendment and cyberspace, etc.). There are 16 such orders, for a total of 160 "slots" for addresses on first ten retrievals in each case. All 16 of these combinations could easily have been input by a person interested in the very same issue (as well as dozens, if not hundreds, of other combinations and small variations on the component terms). The result: Out of the 160 slots, 138 unique different entries were produced. Thus, if each of the 16 queries had been entered by a different person, each person would have missed 128 other "top ten" entries on essentially the same topic, not to mention the additional results that could be produced by the dozens of other terminological and search syntax variations possible on this topic. In sum, the data from these small tests of the World Wide Web conform well with all the other data we have about the wide range of vocabulary people use to describe information and to search on information. If 85 or 90 percent of users employed the same term for a given topic, and only the remainder used an idiosyncratic variety of other terms, we could, with a moderate amount of comfort, endeavor to satisfy just the 85 or 90 percent, by finding that most popular term and using it in indexing the topic. But description of information by people just does not work this way. Even the most frequently used term for a topic is employed by a minority of people. There are generally a large number of terms used, many with non-trivial numbers of uses, and yet no one term is used by most searchers or indexers. For search engines designed as browsers this may be a good thing. The slight variations yield different results sets for searchers, and thus spread around the hits better across the possible sites, thereby promoting serendipity. But for people making a directed search, it is illusory to think that entering that single just-right formulation of the query, if one can only find it, will retrieve the best sites, nicely ranked, with the best matches first. Under these circumstances, any simple assumption about one-to-one matching between query and database terms does not hold. In million-item databases, even spelling errors will usually retrieve something, and reasonable, correctly spelled terms will often retrieve a great many hits. (In one of my search engine queries, I accidentally input the misspelling "chidlren" instead of "children." The first four retrievals all had "chidlren" in the title.) Users may simply not realize that the 300 hits they get on a search--far more than they really want anyway--are actually a small minority of the 10,000 records available on their topic, some of which may be far more useful to the user than any of the 300 actually retrieved. Another possible reason why we have not readily absorbed this counter-intuitive study data: Interaction with a system is often compared to a conversation. Whether or not a person consciously thinks of the interaction that way, the unconscious assumptions can be presumed to derive from our mental model of conversations, because that is, quite simply, the principal kind of interaction model we language-using humans come equipped with. In a conversation, if I say "forest" and you say" forests," or I say" forest management" and you say" management of forests," or I say" forest" and you say "woods," we do not normally even notice that different terms are used between us. We both understand what the other says, each member of the example pairs of terms taps into the same area of understanding in our minds, and we proceed quite happily and satisfactorily with our conversation. It does not occur to us that we routinely use this variety and are still understood. Computer matching algorithms, of course, usually do not generally build in this variety, except for some stemming, because it does not occur to us that we need it. Experienced online database searchers have long understood the need for variety in vocabulary when they do a thorough search. In the early days of online searching, searchers would carefully identify descriptors from the thesaurus of the database they were searching. The better designed the thesaurus and indexing system, the more useful this practice is. However, searchers soon realized that, in many cases where high recall was wanted, the best retrieval set would come from using as many different terms and term variants as possible, including the official descriptors. They would do this by scanning several thesauri from the subject area of the database and entering all the relevant terms they could find, whether or not they were official descriptors in the target database. In some cases, where they had frequent need to search a certain topic, or a concept element within a topic, they would develop a "hedge," a sometimes-lengthy list of OR’d terms, which they would store and call up from the database vendor as needed. (See, e.g., Klatt, 1994.) Sara Knapp, one of the pioneers in the online searching area, has published an unusual thesaurus--not the kind used by indexers to identify the best term to index with, but one that searchers can use to cover the many terms needed for a thorough search in an area (Knapp, 1993). Figure 1 displays the same topic, "Child development," as it appears in a conventional thesaurus, the Thesaurus of ERIC Descriptors (Houston, 1995), and in Knapp’s searcher thesaurus. It can be seen that Knapp’s thesaurus provides far more variants on a core concept than the conventional indexer thesaurus does, including likely different term endings and possible good Boolean combinations.
A popular approach in IR research has been to develop ranking algorithms, so that the user is not swamped with hundreds of undifferentiated hits in response to a query. Ranking will help with the 300 items that are retrieved on the term-that-came-to-mind for the user--but what about the dozens of other terms and term variations that would also retrieve useful material (some of it far better) for the searcher as well? IR system design must take into account these well-attested characteristics of human search term use and matching, or continue to create systems that operate in ignorance of how human linguistic interaction in searching actually functions. All Subject Vocabulary Terms Are Not Equal There is considerable suggestive evidence that the human mind processes certain classes of terms differently from others, i.e., that certain terms are privileged in comparison with others. If so, we can ask how we might take advantage of these characteristics in IR system design.
Folk Classification. There is a substantial body of linguistic and anthropological research into what are called "folk classifications," the sets of categories used by various cultures for plants, animals, colors, etc. (See e.g., Raven, Berlin, & Breedlove, 1971; Ellen & Reason, 1979; Brown, 1984.) As Raven, Berlin, & Breedlove note: In all languages, recognition is given to naturally occurring groupings of organisms. These groupings appear to be treated as psychologically discontinuous units in nature and are easily recognizable. (p. 1210) These they refer to as taxa. Across many cultures, these groupings have been shown to fall into a few class types, which the authors label, going from general to specific: "unique beginner, life form, generic, specific, varietal" (p. 1210). Of these, the "generic" is pivotally important, containing readily recognizable forms such as "monkey" or "bear." The more specific forms, "specific" and "varietal," are generally few in number, and "can be recognized linguistically in that they are commonly labeled in a binomial or trinomial format that includes the name of the generic or specific to which they belong (p. 1210)," such as--in Western cultural terms --"howler monkey" or "Alaskan grizzly bear." The generics are so readily recognized because there are many physical discontinuities that distinguish one from another (Brown, 1984, p. 11). For instance, the shape and appearance of a cow (generic level) is very different from the shape and appearance of a fox (generic level), while the same for a Guernsey cow (specific or varietal) is not so different from the shape and appearance of a Hereford cow (specific or varietal). Raven, Berlin, & Breedlove go on to say:
Folk taxonomies all over the world are shallow hierarchically and comprise a strictly limited number of generic taxa ranging from about 250 to 800 forms applied to plants and a similar number applied to animals. These numbers are consistent, regardless of the richness of the environment in which the particular people live. (p. 1213) So the English-speaking Californian will have a set of names for plants or animals that falls in the same number range as the Yapese speaker on an island in Micronesia or an Eskimo in Canada. (And, no, in contrast to what is commonly stated, even in serious scientific works, Eskimos do not have hundreds of words for "snow," trouncing English with just one or two words for the same phenomenon. Read Pinker, 1994, p. 64ff, as he skewers what he calls the "Great Eskimo Vocabulary Hoax.") A striking discovery in this research on folk classifications has been the observation that formal scientific taxonomies of biological taxa started out, and remained for some time, folk classifications in structure. Several generations of biological taxonomies, including, above all, that of Linnaeus, resemble folk classifications on several structural features. "In broad outlines...the system of Linnaeus was a codification of the folk taxonomy of a particular area of Europe..." (Raven, Berlin, & Breedlove., p. 1211). Both linguistic and anthropological research are more and more frequently demonstrating common underlying patterns across cultures and languages, whatever the particulars of the expression of those patterns in given cultures. I believe, even, that an argument can be made that the Dewey Decimal Classification also betrays some of these same folk classification characteristics. But whether or not Dewey or other formally constituted classifications retain folk classification roots, we can certainly expect the average information system user to approach that system with a mind that creates--and expects to find--classifications with such characteristics. What would these classifications look like? Research was not found that links this research in anthropology with IR research, but we might at least expect, and test for, the pattern described above: shallow hierarchy (few levels), with the generic level of prime significance. In any one area that generic level might contain 250 to 800 terms. If we were to find this pattern in information seeking behavior--that is, people are found to favor use of systems with categories numbered in this range--then the implications for design of access in automated information systems are clear.
Basic Level Terms. Other research has been conducted in psychology that also supports the "not all vocabulary terms are equal" idea. Eleanor Rosch and her colleagues (Rosch et al., 1976; Rosch, 1978) have done extensive research supporting the idea that in natural language vocabulary grouping and use there are what she calls "basic level" terms. As a psychologist, Rosch has endeavored to identify patterns not to compare across cultures, but rather to discover as fundamental human patterns of cognitive processing. She, too, identified the importance of natural discontinuities. She states: A working assumption of the research on basic objects is that (1) in the perceived world, information-rich bundles of perceptual and functional attributes occur that form natural discontinuities, and that (2) basic cuts in categorization are made at these discontinuities. (Rosch, 1978, p. 31) In a long series of studies she found that these basic level terms are the ones that are learned first by children, and are easiest to process and identify by adults (Rosch and others, 1976; Rosch, 1978). Both Rosch (1978, p. 32) and Berlin (1978, p. 24) note the likely correspondence between the generic level in folk classifications and the "basic level" in the psychological studies. She (Rosch and others, 1976) and Newport & Bellugi (1978) even found that the centrality of basic level terms appears in sign language for the deaf. Research throughout the Rosch studies was done on basic level terms (e.g., chair) plus superordinate (e.g., furniture) and subordinate (e.g., kitchen chair) terms. Newport & Bellugi (1978) state regarding the signs in American Sign Language that "superordinate and subordinate signs are usually derived from signs at the basic level: They contain basic-level signs as their components. In short, Rosch’s basic level is formally basic in American Sign Language." (p. 52). When we turn to information science, we do not know if there are basic level search terms used by information system users. Rosch’s work has tantalized the field for many years, but it is not easy to find a way to identify basic level terms when people are talking about topics of interest in information seeking in contrast to Rosch’s very carefully controlled laboratory studies. (See Brown’s efforts to study subject terms from a more psychological perspective--Brown, 1995.) However, the task should not be unsurmountable. Looking at how college students search for material on a topic when assigned to write a paper might reveal patterns in the level of generality of their search terms, for instance. Much more research is needed in this area. However, it would seem to be a reasonable assumption that we would find that certain terms come more commonly to mind for the general user of the Web browser or database, terms that are neither the broadest nor narrowest (i.e., that are "basic level"), and if we could find a way to identify and use those terms for access, system users would make a match much more readily in their searches. Folk Access. The discussion above was about "folk classification." We in information science might also talk about "folk access." There is some evidence that there are identifiable patterns in what people expect of information systems, though much more needs to be studied on this matter. In their study of online catalog design, Kaske & Sanders (1980a, b) found that focus groups responded positively to the idea of some sort of classification tree being available to users at the beginning of their search. My dissertation research (Bates, 1977, p. 371) also uncovered a substantial amount of spontaneous classification behavior on the part of the student participants in a study of the Library of Congress Subject Headings (Library of Congress, 1996). That is, a substantial minority of the students frequently used broad terms with narrower topical subdivisions, despite the fact that such topical subdivisions were forbidden at that time in indexing with Library of Congress subject headings. There are many problems with attempting to offer classified access in the design of subject access systems in manual and automated information systems, and I am not suggesting that access systems should necessarily offer that approach, at least in the conventional sense of classified access in library systems. Rather, I suggest that some sort of design that enables people to approach a digital information system with the feel of classified access may be helpful for users. There will be more on this matter later in the article. Finally, there is another body of evidence about the nature of "folk access." It is an anecdotal truism among reference librarians that users frequently do not say what they really want when they come to a reference desk, but rather ask broader questions. The user who really wants to find out Jimmy Hoffa’s birth date instead asks where the books on labor unions are. In an empirical study of reference interviews, Lynch (1978) found that 13 percent of the several hundred interviews she observed involved shifts from an initial presenting question to a different actual question. Although Lynch did not analyze these shifts in terms of breadth, she did find that the great majority of the 13 percent were cases in which the user presented either a directional question ("Where are the...") or a holdings question ("Do you have [a specific item]"), and it turned out that the person really wanted information on a subject not specific to a particular book. Thomas Eichman has argued persuasively (1978) that this is a quite reasonable approach for users to use in the actual circumstances of the reference interview, and should be expected rather than bemoaned by reference librarians. Usually, the person with a query is approaching a total stranger, and has no idea how much the librarian might know about the subject of interest, or how helpful she will be able or willing to be. Initial interactions constitute "phatic" communication, wherein the user is opening up a channel of communication, sizing up and getting to know the person on the other side of the desk. Eichman argues that in asking an initial broad or general question, the user is much more likely to be able to establish some point of contact with the stranger behind the desk. Consider: if the user asks "Where are the psychology books?", or, "Do you have so-and-so’s Introduction to Psychology?" , can he not have a higher expectation of the librarian’s being able to answer than if he asks for his true information need, a book that can tell him about the Purkinje Effect? Let us suppose, further, that the librarian has, indeed, never heard of the Purkinje Effect. If the user asks for this point-blank, the librarian cannot immediately help him, without asking more questions. The user anticipates that there will be a socially awkward moment, as he gets a blank look from the librarian. If, on the other hand, he starts with the question about psychology books, and the conversation proceeds well, he and the librarian will move through a conversation that makes it clear that the user is interested in visual perception, and the Purkinje Effect is a topic within that area. The librarian, having been given this necessary context, can now, in fact, direct him to the right books in the psychology section, even though she still may not know specifically what the Purkinje Effect is. Starting general, then, would seem to be an effective strategy in the information- seeking conversation between librarian and user. Librarians sometimes fail to recognize the value of this approach from the user, because they (the librarians) are focusing on the technical, professional matter of getting the question answered, just as some physicians bypass the phatic and contextual interactions in a patient interview to get at what they see as the "real business" of diagnosis and treatment. Unfortunately, the patient does not yield up private matters to total strangers so easily, and the professional’s "short" route to the technical content of the interview often founders on its failure to recognize how the interview feels to the user/patient. In broad outline, this movement from general to specific in the course of the reference interaction sounds rather like the pattern of broad term/narrower term noted above in some of the student subject headings. It is as though they expect to connect with the information system by starting broad and working down to the specific: Psychology--Visual Perception--Purkinje Effect. If, as assumed, people carry conversation patterns over into interaction with information systems, then enabling the human user to survey the territory, to size up the system’s offerings before settling down directly to business might equip the searcher with a better understanding of the system’s capabilities, and therefore enable that searcher to submit queries better matched to the strengths of the system. Another part of my dissertation analyzed the match between the student-generated terms and the library subject headings actually applied to the test books. The students without library training more frequently used terms broader than the actual heading applied than they used terms narrower than the correct heading (Bates, 1977, p. 370ff). Other data in my study supported the idea that use of broader terms was a wise (if probably unconscious) strategy on the part of the students. One might expect, a priori, that broader search terms would be easier to match to index terms than narrower ones, because they are usually shorter, simpler, and more generally agreed-upon in phrasing. This indeed proved to be the case. That half of the students who erred most by using broader terms were compared with the half who used the fewest broad terms. The match rates of the former were higher (Bates, 1977, p. 373). In a study of different design, Brooks also confirmed my result, finding that "narrower descriptors are harder for subjects to match to bibliographic records than the other two types (1995, p. 107)." The "other two types" were what he called "topical-level" and "broader." The former were terms assigned to a record by an indexer; broader and narrower terms were those that were broader and narrower in relation to the assigned term.
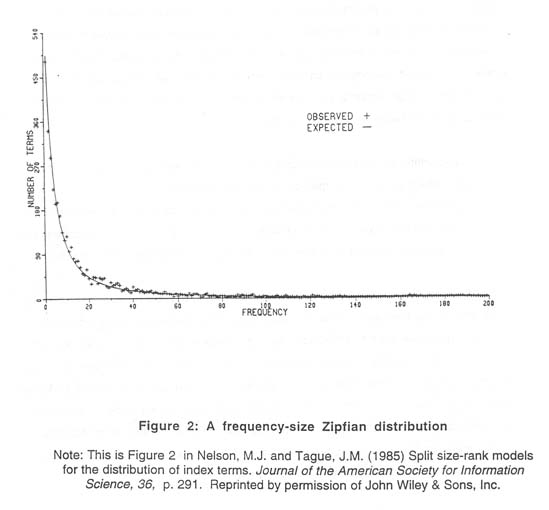
Statistical Indexing Properties of Databases A fair amount of data exists on the statistical properties of databases (though we could benefit from quite a bit more), but these data have seldom been brought to bear on the discussion of indexing and access in IR system design. Here, three statistical features of databases that have implications for indexing and access to digital records will be discussed: Bradford’s Law, vocabulary scalability, and the Resnikoff-Dolby 30:1 rule. Bradford’s Law The first point about statistical properties of databases is that there are very robust underlying patterns/distributions of vocabulary and index terms to be found in bibliographic and full-text databases. It is likely that many people involved with information organization and retrieval have not known or acted upon this fact. Most information-related phenomena have been found to fall into a class of statistical distributions known as Zipfian distributions, named after George Zipf, who published data on the relationship of word frequency to word length (Zipf, 1949). In information science, Samuel Bradford developed what came to be known as Bradford’s Law in describing the distribution of articles on topics through the journal literature (1948). Subsequently, Bradford’s Law was found to appear in a variety of other information-related phenomena (see Chen & Leimkuhler, 1986; Rousseau, 1994). Other Zipfian formulations besides Zipf’s and Bradford’s are the distributions of Yule, Lotka, Pareto, and Price (Fedorowicz, 1982). Over the years there has been extensive debate on the nature of the social processes that produce these distributions, and how best to represent them mathematically (e.g., Brookes, 1977; Chen & Leimkuhler, 1986; Qiu, 1990; Stewart, 1994; Rousseau, 1994). The intention here is not to justify any one Zipfian formulation--for our purposes they look similar--but rather to draw attention to the fact that information-related phenomena fall into this general class of distributions, as do many other distributions associated with human activity. Zipfian distributions have a characteristic appearance which is quite different from the familiar bell-shaped normal distribution that is the usual focus of our statistics courses. Zipfian distributions are characterized by long tails and must often be presented on log paper in order to capture all the data produced in a research study. See Figure 2.
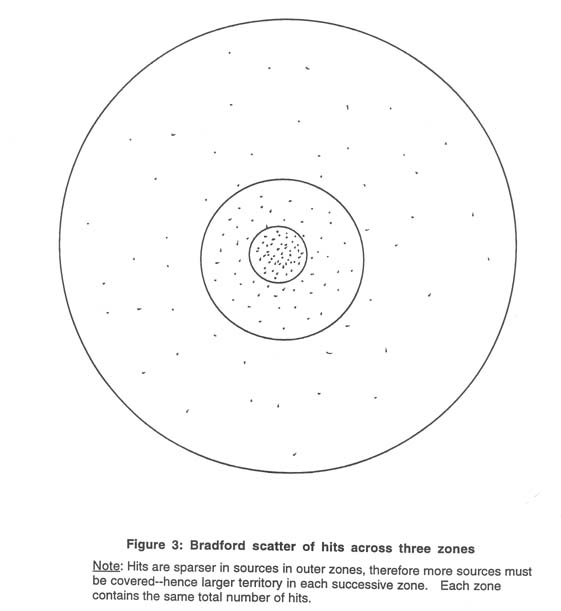
Zipfian distributions are presented as rank-frequency and frequency-size models (Nelson & Tague, 1985). For instance, a rank-frequency distribution of number of index terms assigned in a database displays the frequencies of application of the terms against their rank, with the most frequent being the highest rank (i.e., first). A frequency-size model shows the number of terms assigned in a database at each frequency level. In either case, there is generally a small number of terms with a very high frequency, and a large number of terms with a very low frequency. In Nelson & Tague’s data, for example, approximately one percent of the terms were in the high- frequency portion of the distribution (p. 286). At the other end, the great majority of terms in a typical database might have been applied just once or twice. These distributions are quite robust and defy efforts of thesaurus designers and indexers to thwart them. For instance, librarians have historically used some subdivisions in the Library of Congress Subject Headings to break down large sets of records indexed under the popular high-end terms into smaller sets. For example, "U.S.--History," an enormously popular term, would get another layer of subdivisions to produce headings like "U.S.--History--Revolution, 1775-83," and "U.S.--History--Civil War, 1861-65," and the like. However, the self-similar nature of this type of data indicates that the distribution of the subdivisions will again fall out into a Bradford form within the set of all headings beginning with "U.S.--History" (Rousseau, 1996). Thus some of the combined headings will be very popular and some will have few or one application each, for a mini-Bradford distribution within the larger Bradford distribution. In fact, Zipfian distributions are so common in information-related phenomena that there would be more surprise in finding that such data did not express a Zipfian pattern. To show how far afield this pattern can go, Brookes (1977) reports data from a three-day-long closed conference with 50 people in attendance (pp. 207ff). One of the attending members kept a record of who contributed how many times each to the conference discussion. The results fell into a Bradford pattern, similar to what we have all experienced in school, where some students in class speak very frequently and many hardly at all. To better understand the implications of these distributions for information retrieval, it may be helpful to visualize the Bradford distribution in a different way. When Bradford originally developed his data, he studied the rates at which articles relevant to a certain subject area appeared in journals in those areas. (His two test areas were applied geophysics and lubrication.) He identified all journals that published more than a certain number of articles in the test area per year, as well as in other ranges of descending frequency. He wrote: [I]f scientific journals are arranged in order of decreasing productivity of articles on a given subject, they may be divided into a nucleus of periodicals more particularly devoted to the subject and several groups or zones containing the same number of articles as the nucleus, when the numbers of periodicals in the nucleus and succeeding zones will be as 1:n:n2... (Bradford, 1948, p. 116) In principle, there could be any number of zones, with the number of articles in each zone being the total number of articles divided by the number of zones. In his empirical data, however, Bradford identified just three zones, and three will be used here for simplicity’s sake. Bradford found in his empirical data that the value of "n" was roughly 5. Suppose, then, that someone doing an in-depth search on a topic finds that four core journals contain fully one-third of all the relevant articles found. If the value for n is 5, then 4 X 5 = 20 journals will, among them, contain another third of all the relevant articles found. Finally, the last third will be the most scattered of all, being spread out over 4 X 52 = 100 journals. See Figure 3.
Figure 3 shows that one could find a great many relevant articles on a topic nicely concentrated in a few core journals. But finding the rest of the relevant articles involves an increasingly more extensive search, as the average yield of articles per additional journal examined becomes smaller and smaller the farther out, i.e., the more remotely from the core topic one goes. The Bradford data thus tell us that desired material is neither perfectly concentrated in one place, as we might hope, nor is it completely randomly distributed either, as we might fear. If we assume that Bradford-type distributions of numbers of relevant hits per term in a database could also be arrayed as in Figure 3, then there are some predictable consequences in searching that can be anticipated. When searching with core, "right-on" terms, many relevant hits are retrieved, a high precision result. If, however, some high percentage of all the relevant articles are to be found "farther out," under still related but somewhat more remotely connected terms, then the percentage of good hits per added term goes down, the more remotely related the search term is. The pattern in Figure 3 would thus reflect the classic recall/precision trade-off. The better the recall, the lower the precision, because, as one incorporates more and more remotely related (OR’d) terms in the query, fewer and fewer relevant hits are found. To be confident in finding all relevant items, one would have to go very far afield, scooping up large numbers of records, with more and more remotely related terms, in order to find the occasional relevant item. The new system user who may never have thought about problems of retrieval may assume that a simple query will retrieve all relevant records; the experienced searcher knows that one must go very far afield to catch all relevant materials, and must tolerate increasingly many irrelevant records the farther out one goes. Bradford’s work was very important for special librarians to know about. It demonstrated that an organization that specializes in a certain subject area can readily purchase a good percentage of all relevant materials in its area by buying a small set of core journal subscriptions. But the higher the percentage of relevant materials the library seeks to capture through additional purchases, the smaller the payoff per journal added. The same can be said, of course, of the recall/precision trade-off in IR. So what are the implications of this discussion for indexing digital resources? First, we can expect that even the most beautifully designed system of indexing--whether human or automatic--will produce Zipf-type distributions. If a system has a 10,000-term thesaurus, and a 100,000-record database, and each record has just one term applied to it, each term would then have 10 hits, if the distribution of term applications across the database were perfectly even. The research on these distributions, however, suggests that the distribution will be highly skewed, with some terms applied thousands of times, and a large number of the 10,000 terms applied just once. Further, there is some evidence (Nelson, 1988) that frequencies of term applications in a database are significantly correlated with frequency of terms in queries, i.e., terms popular in indexing are also popular in information needs expressed as queries. So those terms with lots of hits under them will also be used frequently among the queries coming in to the database. This question needs much more research, however. Finally, even in the best-designed database, users will usually retrieve a number of irrelevant records, and the more thorough they are in trying to scoop up every last relevant record by extending their search formulation with additional term variants, the greater the proportion of irrelevant records they will encounter. However, as the "core" terms will probably retrieve a relatively small percentage of the relevant records (certainly under half, in most cases), they must nonetheless tolerate sifting through lots of irrelevant records in order to find the relevant ones. It is the purpose of human indexing and classification to improve this situation, to pull more records into that core than would otherwise appear there, but it should be understood that even the best human indexing is not likely to defeat the underlying Zipfian patterns. Indexers and system designers have to find a way to work with these database traits, rather than thinking they can, through good terminology design, produce a database full of terms each of which falls in some ideal range of ten to fifty hits. The latter, desirable as it may be, is not likely. How then can we design systems to satisfy users, given this robust configuration of database term applications? I do not have any miracle solutions for it, but as long as these patterns are not recognized or understood, we will not even know how to begin to improve retrieval for users. Vocabulary Scalability. Scalability in the development of digital resources is one of the issues currently being discussed (Lynch & Garcia-Molina, 1995). Scalability deals with questions of "scaling up" systems from smaller to larger. Can a system that functions well at a certain size also function well when it is ten or a hundred times larger? This is an important question in information system design, because there is ample reason to believe that there are problems with scaling in this field. Small systems often do not work well when database size expands. New and different forms of organization and retrieval have to be introduced to maintain effectiveness. Evidence of the need to change with growth in size can be detected in the longer history of information organization and access. In the nineteenth century, Charles Cutter developed alphabetical subject indexing ("subject headings") to make growing book collections more accessible. In the 1950’s, when the conceptually broader subject headings began producing too many hits, especially in journal and report collections, "concept" indexing, which forms the basis of most current Boolean-searchable databases, was developed. When manual implementation of concept indexing bogged down on collections of even modest size, computer database searching was developed in the 1970’s for faster searching. Now that databases are exploding into the tens of millions in size, it can be guessed that new responses will again be needed. The purpose in this section is to draw attention to just one statistical feature that bears on scalability in indexing and/or full-text term matching as a means of retrieval from digital resources--the limitations of human vocabulary. It is harder than it might at first seem to estimate the vocabulary size of the average person. Should the words one can produce be counted, or the much larger set one can recognize? Are proper noun names of products, people’s names, etc. counted, or only "regular" lower-case words? How does one count the many morphological variations language creates for many words (e.g., compute, computes, computing, computed)? Here is Pinker (1994) on this question:
The most sophisticated estimate comes from the psychologists William Nagy and Richard Anderson. They began with a list of 227,553 different words. Of these, 45,453 were simple roots and stems. Of the remaining 182,100 derivatives and compounds, they estimated that all but 42,080 could be understood in context by someone who knew their components. Thus there were a total of 44,453 + 42,080 = 88,533 listeme words. By sampling from this list and testing the sample, Nagy and Anderson estimated that an average American high school graduate knows 45,000 words.... (p. 150) This estimate did not include proper names, numbers, foreign words, and other such terms. Not all of the 45,000 words would be suitable for searching for information. On the other hand, college graduates might know more words, including some that are technical terms useful for searching and not in the general vocabulary. So, just to make a general estimate, let us take the closest round-number figure, 50,000, as the vocabulary size of an average information seeker on the Internet or in a digital collection. A recent study found that 63 percent of the search terms employed by scholar searchers of databases were single-word terms (Siegfried, Bates, & Wilde, 1993, p. 282). (Solomon, 1993, also found that children overwhelmingly used single-word search terms.) So if users mostly employ single word terms, let us, for the moment deal with just single-word indexing terms. Let us further assume that we have a million-item database--small by today’s standards. We did arithmetic like this in the previous section--with 50,000 core terms available for searching by the user, and if the frequency in the database for each term were precisely even across the database, then each index term would have to have been applied to exactly 20 records (1,000,000/50,000). Such multiple uses of each term cannot be avoided when the size of the database is so much larger than the size of the indexing vocabulary. But that assumes that only one term is applied per record. In fact, it is common for anywhere from ten to forty terms to be applied per record in human-indexed bibliographic databases, and, of course, indefinitely many--easily hundreds or more--words are indexed in each record in a full-text databases. Let us suppose our little million-item bibliographic database has an average of twenty index terms per record. Then, if the distribution of terms across the database were again exactly level, each term would have 400 hits. This is a very problematic hit rate--it is far more than most people want. But we have only just begun. With natural-language indexing of the abstracts, let us suppose there are 100 indexable words per record, then if the application of words across the million-item database is level, there will be 2000 hits for every indexable term used in the database. With digital libraries and the Internet, where tens of millions of records are currently involved, 20,000 or 50,000 or 100,000 hits per word can easily become the minimum on the assumption of level application of terms across the database. There is no avoiding these statistics. As a database grows, the number of words a human being knows does not grow correspondingly. Consequently, the average number of hits grows instead. It can be expected from the Bradford data, however, that the actual number of hits will be highly skewed, so some will have tens of thousands of hits and other terms very few. Further, if the popular terms are also popular in queries, per Nelson’s data (1988), then a high proportion of all the queries will be pulling up that small set of terms with the huge numbers of hits. To be sure, a searcher is not limited in most cases to single-word terms. The use of implicit or explicit Boolean logic in a query makes possible the combination of two or more words and usually drastically reduces the number of retrievals. Indeed, based on my own experience, I would estimate that a study on databases in the one- million to five-million item range would find that the best starting point for a search is to use two words or two concepts; that is, such a combination will most often produce sets of tolerable size. One-word searches produce too many high-hit searches and three-word (or concept) searches produce too many zero or low-hit searches. It remains to be seen whether three-word queries are optimal for searches on mega-databases of tens of millions of records. Other problems arise at this point, however. There are astronomically many different combinations possible for even just two- and three-word phrases. If every one of our searcher’s 50,000 words can be combined with every other one, then there will be just under 2.5 billion possible combinations for the two-word combinations alone. As we learned in an earlier section, varying the search terms by just morphological changes (not even included in that 50,000 figure)--"violence" to "violent," for example, produced substantial changes in the retrieved set, and varying by synonymous or near-synonymous terms often produced results that were entirely different. So, by using more than one term, we succeed in reducing the retrieved set, but in ways that are quite unpredictable in relation to the question of which set of records will most please the searcher. How can I know a priori whether I should use "violent" or "violence" to find the hits that would most please me if I could somehow look at all the records and determine which ones I would like? What if I think of "freedom of speech" and "cyberspace" and do not think of the other fifteen combinations discussed earlier for this topic? Brilliant ranking algorithms for the retrieved set will have no impact on the many relevant unretrieved records. The distribution of frequency of use of two-word combinations will probably fall out into a Bradford distribution too, so there will be the usual problem of some combinations with very many hits and many combinations with few or no hits. The "perfect 30-item search" that we all want from databases--actually, say, a range of 10-50 items--will likely occupy a small part of the entire distribution of hits in a database of almost any size--with most of the match rates being substantially larger or smaller. For browsing purposes, the current indexing along with the ability to go in any of thousands of directions--sometimes with just the change of a character or two in a search statement (and, of course, also by following up hypertextual links)--makes the World Wide Web entertaining and sometimes informative. But active, directed searching for even a moderately focused interest, has yet to be provided for effectively for data collections of the size available on the Net. The time has clearly arrived to develop a next round of innovations as information stores scale up another explosive level. The general assumption has been that the needed innovations will be all automatic. Certainly, the solution will require substantial automated production, but what has been discussed so far in this article surely indicates that some role for human intervention is needed too. Algorithms based on current designs, or even enhancements of current designs, cannot deal with the many issues raised here.
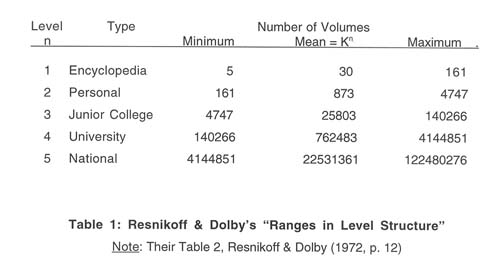
Resnikoff-Dolby 30:1 Rule Earlier, in discussing Bradford-type distributions in information-related phenomena, we had to contemplate the possibility that our many individual actions and decisions as information system designers and information providers and users, however motivated by individual choice and need, nonetheless fall out into remarkably persistent and robust statistical patterns. In examining the Resnikoff-Dolby 30:1 rule we will discover an even more striking and hard-to-credit statistical pattern, which is nonetheless backed up by considerable data. Under a grant from the Department of Health, Education, and Welfare, Howard Resnikoff and James Dolby researched the statistical properties of information stores and access mechanisms to those stores (Resnikoff & Dolby, 1972; Dolby & Resnikoff, 1971). Again and again, they found values in the range of 28.5:1 to 30:1 as the ratio of the size of one access level to another. For mathematical reasons, they used K=29.55 as the likely true figure for their constant, but they and I will use 30 for simplicity’s sake in most cases. They found from their data: •A book title is 1/30 the length of a table of contents in characters on average (Resnikoff & Dolby, 1972, p. 10). •A table of contents is 1/30 the length of a back of the book index on average (p. 10). •A back of the book index is 1/30 the length of the text of a book on average (p. 10). •An abstract is 1/30 the length of the technical paper it represents on average (p. 10). •Card catalogs had one guide card for every 30 cards on average. Average number of cards per tray was 30,2 or about 900 (p. 10). •Based on a sample of over 3,000 four-year college classes, average class size was 29.3 (p. 22). •In a test computer programming language they studied, the number of assembly language instructions needed to implement higher-level generic instructions averaged 30.3 (p. 96). All these results suggest that human beings process information in such a way as to move through levels of access that operate in 30:1 ratios. Resnikoff and Dolby did not use this term, but I think a good name for it would be: Information Transfer Exchange Ratio. Something about these size relationships is natural and comfortable for human beings to absorb and process information. Consequently, the pattern shows up over and over again. But Resnikoff and Dolby’s research did not stop there. They found that book superstructures as well tended to cluster around multiples of 30. Drawing on library statistical data, they found that junior college libraries clustered around 29.553 volumes, or 25,803; university libraries clustered around 29.55,4 or 762,483. The next level up, 29.55,5 or 22,531,361, represented what they called a national library (Library of Congress) level. We would now add bibliographic utilities, such as OCLC, and, of course, Web browsers. With the spectacular growth of the Internet, we may soon expect to need to be able to provide access to resources in the 29.556 range, or, in the 660-million range. Of course, not all libraries or books fit the above averages. Libraries are constantly growing, and figures could be expected not to rest strictly on average points. But Resnikoff and Dolby did find that the data clustered fairly tightly around these means (p. 92). The largest item at one level seldom exceeded the smallest item at another (p. 90). Resnikoff and Dolby suggested that the line between two access levels should be drawn in the following manner: Mathematically, the natural way to define a boundary between two values on an exponentially increasing scale is to compute the geometric mean of the two values. (p. 12) Their table listing these range values (p. 12), is adapted as Table 1 below.
Resnikoff and Dolby bring mathematical and physical arguments to bear in support of why this pattern appears, which will not be reproduced here. As they note: The access model presented in this chapter is not restricted to the book and its subsystems and supersystems. There is considerable evidence that it reflects universal properties of information stored in written English form, and, in a slightly generalized version, may be still more broadly applicable to the analysis and modeling of other types of information systems such as those associated with the modalities of sensory perception. These wide ranging and difficult issues cannot be examined here in a serious way; moreover, we do not yet have sufficient data upon which a definitive report can be based. (p. 93) To demonstrate results with such wide-ranging significance would indeed require vast amounts of data, more than one funded study could possibly produce. But Resnikoff and Dolby do bring forth a great deal of data from a wide variety of environments--more than enough to demonstrate that this is a fertile and very promising direction for research to go. (See also Dolby & Resnikoff, 1971. Later, Resnikoff, 1989, pursued his ideas in a biophysical context, rather than in library and information science applications.) While there are hundreds, if not more, papers pursuing questions related to Bradford distributions, this fascinating area of research has languished.* _______ *For those unable to access the ERIC technical report, Howard White et al. (1992) have a brief summary and discussion on pp. 271. White says there that in writing my paper "The Fallacy of the Perfect 30-Item Online Search" (1984) I did not know of Dolby’s work. That is not strictly true. I took a class from Dolby when I was a graduate student at the University of California at Berkeley, where he mentioned the 30:1 ratio and some of the instances where the ratio had been found. The class preceded the publication of the technical report, however, and I did not know until White wrote his chapter that Dolby’s figure was based on extensive data and had been published through ERIC. Had I known of the work, I would have addressed it in my own analysis of book indexes, tables of contents, etc., in Bates (1986b). Indeed, one may ask why these promising data have not been followed up more in the years since. When I have presented them, there is a common reaction that these relationships sound too formulaic or "gimmicky," that there could not possibly be such remarkable regularities underlying the organization of information resources. There has also been a strong shift in the years since from physical interpretations of information to constructivist views, which see each event or experience as uniquely constructed by the person doing the experiencing. I would argue that there are nonetheless regularities underlying our "unique" experiences, that while the individual construction of a situation generally cannot be predicted, there are often strong statistical patterns underlying human behavior over a class of events. We will find that there is no fundamental contradiction in the physical/statistical and the social/constructivist views; only a failure to accept that they can, and do, operate at the same time. Equipped with the ideas in the Resnikoff-Dolby research, it is possible to see how certain results in the research literature--done independently of Resnikoff and Dolby’s work--in fact fit nicely within the framework of their model of information. Wiberley, Daugherty, & Danowski did successive studies on user persistence in displaying online catalog postings, first on a first-generation online catalog (1990), and later on a second-generation online catalog (1995). In other words, they studied how many postings users actually examined when presented with a hit rate of number of postings found when doing a search in an online catalog. They summarize the results of both studies in the abtract of the second (1995): Expert opinion and one study of users of a first-generation online catalog have suggested that users normally display no more than 30 to 35 postings. .... Analysis of transaction logs from the second-generation system revealed that partially persistent users typically displayed 28 postings, but that overloaded users did not outnumber totally persistent users until postings retrieved exceeded 200. The findings suggest that given sufficient resources, designers should still consider 30 to 35 postings typical persistence, but the findings also justify treating 100 or 200 postings as a common threshold of overload. (p. 247) Note the parallels between this data and that in Table 1 above. Resnikoff and Dolby’s level 1 shows a mean of 30 items, with a maximum of 161. In the Wiberley, Daugherty, and Danowski research, people feel comfortable looking at 30 items, and will, if necessary go up to "100 or 200" (ideally, 161?), but beyond that figure go into overload. Another parallel appears in the research on library catalogs. Time and time again, when asked, catalog users say they want more information, an abstract or contents list, on the catalog record (Cochrane & Markey, 1983). Resnikoff & Dolby discuss at some length questions of the role the catalog plays, in terms of levels of access, to the collection. The argument will not be made here in detail, but both bodies of data converge on the idea that people need another 30:1 layer of access between the catalog entry and the book itself. This need shows up in the request for an abstract or summary, presumably 30 times as long in text as the average book title or subject heading. The Resnikoff & Dolby research also clearly needs to be related to the research on menu hierarchies in the human computer interaction literature (e.g., Fisher, Yungkurth, & Moss, 1990; Jacko & Salvendy, 1996). Finally, at many points in their analysis Resnikoff and Dolby work with the lognormal distribution: "These examples and others too numerous to report here prompt us to speculate that the occurrence of the lognormal distribution is fundamental to all human information processing activities (p.97)" That distribution is one of the common candidates for modeling Zipfian distributions (see Stewart, 1994). Those with more mathematical expertise than I will surely be able to link these two bodies of data in a larger framework of analysis. It may yet be found that human information processing characteristics are the underlying driving force behind many other seemingly random or unpredictable statistical characteristics of the information universe. If so, it may be discovered that the two seemingly disjoint approaches taken so far in this paper, the "Human Factors" and the "Statistical Indexing Properties of Databases," are, in fact, very closely linked and both derive from common sources.
Domain-Specific Indexing Research emanating from two areas of study strongly indicates that attention to subject domain in the design of content indexing and access has potentially high payoff in improved results for users. Research in computational linguistics and automatic translation has increasingly been looking to sub-domains of language as more productive venues for improving effectiveness in application of automatic techniques (Kittredge & Lehrberger, 1982; Grishman & Kittredge, 1986). The value of sublanguage analysis is beginning to be recognized and studied in information science as well (Haas & He, 1993; Liddy, Jorgensen, Sibert, & Yu, 1993; Losee & Haas, 1995). Research in library and information science on domain vocabularies for indexing and retrieval has likewise demonstrated the importance of domain in the provision of access to resources. Stephen Wiberley has demonstrated that the character of the humanities vocabulary does not match the conventional assumptions that such vocabulary is fuzzy and hard to pin down (Wiberley, 1983, 1988). Nor is the vocabulary similar in character to natural and social scientific vocabulary, according to a study carried out at the Getty Information Institute (Bates, Wilde, & Siegfried, 1993). That study found several classes of vocabulary types used in the humanities literature that were virtually non-existent in the science literature. Tibbo (1994) surveys the distinct issues associated with humanities indexing, Swift, Winn, & Bramer (1979) draw attention to unique characteristics of social science vocabulary, and Pejtersen applies domain analysis to fiction classification (1994). Weinberg (1988) also makes a strong case for a whole different class of access to information, viz., aspect, or comment, as distinct from the usual "aboutness" that index-descriptive terms are intended to provide. This sort of information would be particularly valuable for the humanities and the "softer" social sciences. Yet it is the characteristics of scientific and engineering vocabulary that have driven most of the theory of indexer thesaurus development since World War II. Likewise, Mavis Molto, who was interested in developing automated techniques for genealogical literature, found that the distribution of term types in that literature is very different from general text at large, and that means of optimizing retrieval in such text may be quite different from those assumed previously (Molto, 1993). These results suggest dramatic differences in the character of vocabulary and information needs across the various intellectual domains. Techniques that work well in one may not work well in another. There are other reasons, as well, for suspecting that treatment of the various intellectual domains as though all vocabularies are equal is an ineffectual and sub-optimal approach. Research in the sociology of science (Merton, 1973; Meadows, 1974) and scholarly communication (Morton & Price, 1986; Bakewell, 1988; Bates, 1994, 1996a) demonstrate a number of fundamental differences in how scholars and scientists conceptualize their research problems, in how paradigms do and do not function in various domains, in how social processes and relationships among researchers function differently in one domain as compared to another, and on and on. We should rather assume that these many differences do make a difference in means to optimize access to recorded materials than that they do not--at least until such time as we have much more research in hand on the effectiveness of various access techniques and vocabulary types. Recently, Hjorland and Albrechtsen (1995) made an extensive and cogent argument for the value of domain analysis in information science. Their argument will not be adumbrated here, except to quote them briefly: The domain-analytic paradigm in information science (IS) states that the best way to understand information in IS is to study the knowledge-domains as thought or discourse communities, which are parts of society’s division of labor. Knowledge organization, structure, co-operation patterns, language and communication forms, information systems, and relevance criteria are reflections of the objects of the work of these communities and their role in society. The individual person’s psychology, knowledge, information needs, and subjective relevance criteria should be seen in this perspective. ( p. 400) Much could be written and hypothesized, well beyond the scope of this article, on how domain factors might affect retrieval. The goal here, however, is rather simply to establish in general the importance and value of paying attention to domain as a way to improve retrieval. So the final argument to be brought forth is a practical, real-world one, a description of a database that uses domain analysis and has met the test of the marketplace. BIOSIS, the database of biological periodicals, is just one of several that might serve as examples, but illustrates particularly well the points being made in this section. The database contains over 10 million records and adds over half a million records per year (BIOSIS Search Guide, 1995, p. A-3), so it represents a very large body of information with, as we shall see, substantial value added in the handling of its indexing, both human and automatic. The developers of BIOSIS studied the literature of the field and the needs of their users, and created a resource that serves many of the distinctive needs of the biological research community. Articles are coded for whether they describe a new species, for example, a likely important question for many biologists searching the database. But the analysis of the literature of the field goes much deeper than that. In the end, the database makes available two broad classes of information--taxonomic (descriptions of species and broader classes of flora and fauna) and general subject information. These are, in turn, broken out in ways likely to be of particular value in the study of biology. The Biosystematic Index provides searchable codes for taxonomic levels discussed in articles above the genus-species level. At the species level, species can be searched by the user as free text on the subject-related fields of the record. Retrieval is improved, however, by the indexers at BIOSIS, who add species names to the basic bibliographic description of the article in every case that they are mentioned in the text of the article but not in the title or abstract. General subject topics are, likewise, approached at both broad and specific levels. Broad, popular concepts, the sort that recur frequently in the biological literature, have been identified and carefully described and analyzed for both indexers and searchers. Such broad concepts include things like animal distribution, wildlife management, and reproduction. Because these are both common and broad, searching on these terms alone or with a species name could lead to very large and wildly varying retrieval sets, depending on which particular terms for the concept had been used by the article’s writer, the indexer, or the searcher. Because of the importance of these concepts (they are clearly at the upper end of the Bradford distribution), it has paid off for BIOSIS to analyze these terms closely and define them precisely for both indexers and searchers. These terms are called "concept codes." For example, Figure 4 displays the entry in the BIOSIS search manual for the concept code for Animal Communication:
On the other hand, less common subject terms, those that are more specific and narrowly applicable and often at the low end of the Bradford distribution, do not receive this elaborate analysis. They are, instead, not even indexed in any formal way; they are just made free-text searchable. BIOSIS helps the searcher improve results, however, by providing a search manual containing the more popular of these free-text terms. For the less popular terms, or terms newly appearing since the last manual, the searcher knows to use them anyway, because the list of terms in the manual is explicitly stated to include only the more popular terms, and not all legitimate ones, as is usual with thesauri. BIOSIS has thus cleverly worked simultaneously with the character of the domain and its practitioners’ information needs, the character of the terminology important in the domain, and the statistical character of the literature in the domain, to produce a database that enables fast, high-recall, high-precision retrieval.
Discussion and Conclusions Having reviewed these various issues, we come to the next natural question: How can these things we have learned be applied to improve IR system design for the new digital information world? In the previous section the BIOSIS database of biological literature was brought forth as an example demonstrating a good understanding of and use of domain factors in the design of indexing for very large databases. Special indexes and retrieval capabilities probed precisely the kinds of information of most interest and use to biologists. Further, as was noted there, BIOSIS also effectively uses the Bradfordian statistical properties of its material, by indexing deeply and carefully the core concepts in biology that recur frequently in the literature and therefore constitute the high-frequency end of the Bradford curve. The BIOSIS database constitutes one solution that integrates both database statistical factors and subject domain factors in its design. It demonstrates that the seemingly intractable Bradfordian characteristics--the massively skewed distributions that typically characterize meaningful collections of information--need not be defeated in order to effectuate good information retrieval. Rather, these statistical characteristics can be worked with, the system design ingeniously set up to invest high indexing effort in the high-demand end of the curve, and low effort, largely automatic, in the low-demand end. There are no doubt other such inspired mixes of human and system effort possible throughout the information world, once the underlying factors are understood. One area that remains to be studied much more is that of the Resnikoff-Dolby 30:1 rule. If, as the evidence to date suggests, people often like to move down through a hierarchy of some sort as they access information, various kinds of hierarchical arrangements could be developed with layers sized in a 30:1 ratio. Many systems currently are being developed with the structure of classical hierarchical (family-tree style) classification schemes. In library and information science, however, such classifications are frequently seen to be less effective than classifications based on faceted principles, developed some decades ago by S.R. Ranganathan (1963) but only now coming into their full fruition. Examples of faceted approaches can be seen in the Getty Art & Architecture Thesaurus and in the Predicasts business database. Faceting provides a flexibility and power much in excess of the limited character of conventional hierarchical schemes--not unlike the advance represented by relational databases in the database world. (A brief, simplified comparison of the two types of classification scheme is provided in Bates, 1988. See Rowley, 1992, or Vickery, 1968, for more thorough introductions.) Using this and other indexing techniques in combination with a sensitivity to database and domain factors can produce great retrieval power. Whether and how these techniques can be used to good effect in multi-million-item collections remains to be seen. However, of all the issues raised in this article, those in the first section, on human factors, have been least attended to in system design (see also Chen & Dhar, 1990). Little research in information science has examined the various folk classification issues raised in this article--whether people spontaneously use terms that fall into groupings fitting the characteristics of folk classifications, whether there are Roschian "basic level" terms (see also Brown, 1995), and so on. Many design changes need to be made in information systems in response to the research on the great variety of terms generated by people for a given topic. Until we fully accept that reality, and build information retrieval systems that intelligently incorporate it, systems will continue to under-perform for users. It is interesting to note, however, that two different information systems, designed for two radically different environments, independently came up with solutions involving the collecting and clustering together of variant terms around core concepts. The Los Angeles Department of Water and Power, with more than 10,000 employees, needed to solve a thesaurus problem for their multi-million item records management database. The records would be input into the system by clerks who often had only a high school education and no concept of vocabulary control, and retrieved by any and everyone in the organization up to and including the General Manager. The content range of the vocabulary needed for retrieval was very wide--engineering, real estate, customer relations, construction, names of organizations, officers, etc. The solution proposed (Bates 1990), which was subsequently implemented, was to use highly skilled human labor to create and update continuously a cluster thesaurus of closely related term variants, based on a close monitoring of database contents and relevant technical thesauri. (In this way, only one person, the thesaurus developer, needed to have lexicographical expertise, rather than expecting every clerk in the organization to develop it.) When a searcher used any one of the terms, the variants could be called up too. The searcher was then given the option of searching on all or selected terms from the cluster. The person searching on "transmission line right of way" might think no variants are needed until the cluster appears with a dozen or more other ways the concept has been described in the database (some examples: transmission line easements, T/L Right of Way, T/L ROW). Meanwhile, at the Getty Information Institute, the rarefied world of art historical scholarship was likewise being served by a database developed to cluster term variants--in this case various forms of artists’ names, in the Union List of Artist Names (1994). Just as it was impractical at the Water and Power Department to get all the department’s memo and report writers to use the same word for the same concept, it is also undesirable to try to search on an artist’s name under just one form. Artists have frequently been known by both vernacular and Latin names, by different names in different languages, and by nicknames and formal names. They may be referred to in all these forms in the literature of interest to a researcher, and the researcher may not initially be aware of all the forms that have been used. Consequently, provision of a database containing all those forms not only aids in retrieval effectiveness, but is an important scholarly resource in its own right. The Getty Information Institute has been experimenting with making this and two other thesaural databases, Art & Architecture Thesaurus (Peterson, 1994), and Thesaurus of Geographic Names, available on the Internet. As of this writing, two of the three are combined in a online thesaurus named "a.k.a.", which can be used during an experimental period by people searching the Getty bibliographic databases via the World Wide Web (http://www.ahip.getty.edu/aka/). Searching on the artist "Titian" yielded the names of five different individuals who have been known by this name, as well as all the variants found on each individual’s name. One of these five, Tiziano Vecellio, has been known by at least 46 different names, according to the Union List of Artist Names. Examples include the following: Detiano, Titsiaen, Tizzani, Vecelli, and Ziano. This term-variant database provides a nice example of ways in which online access can be improved in real time for Internet or other online searchers. A number of other experimental systems and approaches are currently being developed to improve vocabulary for users for search and retrieval as well (Chen & Lynch, 1992; Kristensen, 1993; Chen & Ng, 1995; Chen, Yim, Fye, & Schatz, 1995; Johnson & Cochrane, 1995; Jones, Gatford, Robertson, Hancock-Beaulieu and others 1995; Larson, R.R.; McDonough, J.; O’Leary, P.; Kuntz, L.; & Moon, R., 1996; Schatz, Johnson, Cochrane, & Chen, 1996). Both the Water and Power and the Getty systems rely on a valuable aspect of human cognition that is unfortunately much ignored in the information system design world: people can recognize information they need very much more easily than they can recall it. The average person will recall (think up) only a fraction of the range of terms that are used to represent a concept or name, but can take in a screen full of variants in an instant, and make a quick decision about desired terms for a given search. Most current information systems require that the searcher generate and input everything wanted. People could manage more powerful searches quickly if an initial submitted term or topic yielded a screen full of term possibilities, related subjects, or classifications for them to see and choose from (see also Bates, 1986a). These and other experiments in improved access are made possible if indexing is separated from access in the design of an information system. By separating these two, the user front-end can be designed around the distinctive traits and evolutionary adaptations of human information processing, while the internal indexing describing the document may be different. Changes in our developing understanding of human cognition in information seeking situations, and changes in vocabulary can relatively quickly be accommodated in a user-oriented front-end, without requiring the re-indexing of giant databases. In sum, the pieces of knowledge reviewed here have yet to be unified into a single grand model. Much research remains to be done. However, there are tantalizing hints that seemingly dramatically different features presented herein--such as the human and statistical factors--may indeed ultimately be given a unified formulation, once research and theory development have progressed far enough. From what is already known, however, it can be seen that we need to design for the real characteristics of human behavior as people have information needs and confront information systems to try to meet those needs. We know, further, that robust underlying statistical properties of databases demand that we find ingenious ways to work with these statistical patterns, rather than deny or ignore them. Finally, indexing and information system design needs to proceed within the context of a deep understanding of the character of the intellectual domain, its culture, and its research questions. Any design lacking understanding of these human, database, and domain elements will almost certainly sub-optimize information retrieval from digital resources and the Internet . References Bakewell, E. (1988) Object, image, inquiry: The art historian at work. Santa Monica, CA: Getty Art History Information Program. Bates, M.J. (1977) System meets user: Problems in matching subject search terms. Information Processing & Management, 13, 367-375. Bates, M.J. (1984) The fallacy of the perfect thirty-item online search. RQ, 24, 43-50. Bates, M.J. (1986a) Subject access in online catalogs: A design model. Journal of the American Society for Information Science 37, 357-376. Bates, M.J. (1986b) What is a reference book? A theoretical and empirical analysis. RQ, 26, 37-57. Bates, M.J. (1988) How to use controlled vocabularies more effectively in online searching. Online, 12, 45-56. Bates, M.J. (1989a) The design of browsing and berrypicking techniques for the online search interface. Online Review, 13, 407-424. Bates, M. J. (1989b) Rethinking subject cataloging in the online environment. Library Resources & Technical Services, 33, 400-412. Bates, M.J. (1990). Design for a subject search interface and online thesaurus for a very large records management database. In Proceedings of the 53rd ASIS Annual Meeting. (pp. 20-28). Medford, NJ: Learned Information. Bates, M.J. (1994) The design of databases and other information resources for humanities scholars: The Getty Online Searching Project report no. 4. Online and CDROM Review, 18, 331-340. Bates, M.J. (1996a) Document familiarity, relevance, and Bradford’s Law: The Getty Online Searching Project report no. 5. Information Processing & Management, 32, 697-707. Bates, M.J. (1996b). The Getty end-user online searching project in the humanities: Report no. 6: Overview and conclusions. College & Research Libraries, 57, 514-523. Bates, M.J.; Wilde, D.N.; & Siegfried, S. (1993) An analysis of search terminology used by humanities scholars: The Getty Online Searching Project report no. 1. Library Quarterly, 63, 1-39. Belkin, N.J. (1982) ASK for information retrieval. Part 1:Background and theory. Journal of Documentation 38, 61-71. Belkin, N.J.; Kantor, P.; Fox, E.A.; & Shaw, J.A. (1995) Combining the evidence of multiple query representations for information retrieval. Information Processing & Management, 31, 431-448. Berlin, B. (1978) Ethnobiological classification. In E. Rosch, & B.B. Lloyd (Eds.), Cognition and categorization (pp. 9-26), Hillsdale, NJ: Lawrence Erlbaum. BIOSIS Search Guide. (1995) 1995 Ed. Philadelphia, PA: BIOSIS. Blair, D.C. (1996) STAIRS redux: Thoughts on the STAIRS evaluation, ten years after. Journal of the American Society for Information Science, 47, 4-22. Borgman, C.L. (1996) Why are online catalogs still hard to use? Journal of the American Society for Information Science, 47, 493-503. Bradford, S.C. (1948) Documentation. London: Crosby Lockwood. Brookes, B.C. (1977) Theory of the Bradford Law. Journal of Documentation, 33, 180-209. Brooks, T.A. (1995) People, words, and perceptions: A phenomenological investigation of textuality. Journal of the American Society for Information Science, 46, 103-115. Brown, C.H. (1984) Language and living things: Uniformities in folk classification and naming. New Brunswick, NJ: Rutgers University Press. Brown, M.E. (1995) By any other name: Accounting for failure in the naming of subject categories. Library & Information Science Research, 17, 347-385. Chen, H., & Dhar, V. (1990) User misconceptions of information retrieval systems. International Journal of Man-Machine Studies, 32, 673-692. Chen, H., & Lynch, K.J. (1992). Automatic construction of networks of concepts characterizing document databases. IEEE Transactions on Systems, Man, and Cybernetics, 22, 885-902. Chen, H., & Ng, T. (1995). An algorithmic approach to concept exploration in a large knowledge network (automatic thesaurus consultation): Symbolic branch-and-bound search vs. connectionist Hopfield net activation. Journal of the American Society for Information Science, 46, 348-369. Chen, H.; Yim, T.; Fye, D.; & Schatz, B. (1995) Automatic thesaurus generation for an electronic community system. Journal of the American Society for Information Science, 46, 175-193. Chen, Y.S., & Leimkuhler, F.F. (1986). A relationship between Lotka’s law, Bradford’s Law, and Zipf’s Law. Journal of the American Society for Information Science, 37, 307-314. Cochrane, P.A., & Markey, K. (1983) Catalog use studies--before and after the introduction of online interactive catalogs: Impact on design for subject access. Library and Information Science Research, 5, 337-363. Dolby, J.L., & Resnikoff, H.L. (1971) On the multiplicative structure of information storage and access systems. Interfaces: The Bulletin of the Institute of Management Sciences, 1, 23-30. Eichman, T.L. (1978) The complex nature of opening reference questions. RQ, 17, 212-222. Ellen, R.F., & Reason, D., (Eds.) (1979) Classifications in their social context. New York: Academic Press. Ellis, D. (1996) The dilemma of measurement in information retrieval research. Journal of the American Society for Information Science, 47, 23-36. Fedorowicz, J. (1982) The theoretical foundation of Zipf’s Law and its application to the bibliographic database environment. Journal of the American Society for Information Science, 33, 285-293. Fidel, R. (1994) User-centered indexing. Journal of the American Society for Information Science, 45, 572-576. Fisher, D.L.; Yungkurth, E.J.; & Moss, S. M. (1990) Optimal menu hierarchy design--syntax and semantics. Human Factors, 32, 665-683. Furnas, G.W., Landauer, T.K., Dumais, S.T., & Gomez, L.M. (1983). Statistical semantics: Analysis of the potential performance of key-word information systems. Bell System Technical Journal, 62, 1753-1806. Gomez, L.M., Lochbaum, C.C., & Landauer, T.K. (1990). All the right words: Finding what you want as a function of richness of indexing vocabulary. Journal of the American Society for Information Science, 41, 547-559. Green, R., & Bean, C.A. (1995) Topical relevance relationships. II. An exploratory study and preliminary typology. Journal of the American Society for Information Science, 46, 654-662. Grishman, R., & Kittredge, R. (Eds.) (1986) Analyzing language in restricted domains: Sublanguage description and processing. Hillsdale, NJ: Lawrence Erlbaum. Haas, S.W., & He, S. (1993) Toward the automatic indentification of sublanguage vocabulary. Information Processing & Management, 29, 721-732. Harter, S. P. (1992) Psychological relevance and information science. Journal of the American Society for Information Science, 43, 602-615. Hert, C.A. (1996) User goals on an online public access catalog. Journal of the American Society for Information Science, 47, 504-518. Hjorland, B., & Albrechtsen, H. (1995) Toward a new horizon in information science: Domain-analysis. Journal of the American Society for Information Science, 46, 400-425. Houston, J.E., (Ed.) (1995) Thesaurus of ERIC Descriptors. 13th ed. Phoenix, AZ: Oryx. Jacko, J.A., & Salvendy, G. (1996) Hierarchical menu design--breadth, depth, and task complexity. Perceptual and Motor Skills, 82, 1187-1201. Johnson, E.; & Cochrane, P. (1995) A hypertextual interface for a searcher’s thesaurus. In Proceedings of Digital Libraries ‘95. Austin, TX, June 11-13, 1995. (pp. 77-86) College Station, TX: Hypermedia Research Laboratory. Jones, S., Gatford, M., Robertson, S., Hancock-Beaulieu, M., and others. (1995) Interactive thesaurus navigation: Intelligence rules OK? Journal of the American Society for Information Science, 46, 52-59. Kaske, N.K., & Sanders, N.P. (1980a) Evaluating the effectiveness of subject access: The view of the library patron. Proceedings of the 43rd Annual ASIS Meeting, 17, 323-325. Kaske, N.K., & Sanders, N.P. (1980b) On-line subject access: The human side of the problem. RQ, 20, 52-58. Kittredge, R., & Lehrberger, J. (1982) Sublanguage: Studies of language in restricted semantic domains. New York: Walter de Gruyter. Klatt, M.J. (1994). An aid for total quality searching: Developing a hedge book. Bulletin of the Medical Library Association, 82, 438-441. Knapp, S.D. (comp. & ed.) (1993). The contemporary thesaurus of social science terms and synonyms: A guide for natural language computer searching. Phoenix, AZ: Oryx. Kristensen, J. (1993) Expanding end-users’ query statements for free text searching with a search-aid thesaurus. Information Processing & Management, 29, 733-744. Kuhlthau, C.C. (1993) Seeking meaning: A process approach to library and information services. Norwood, NJ: Ablex. Larson, R.R.; McDonough, J.; O’Leary, P.; Kuntz, L.; & Moon, R. (1996) Cheshire II: Designing a next-generation online catalog. Journal of the American Society for Information Science, 47, 555-567. Leonard, L.E. (1977) Inter-indexer consistency studies, 1954-1975: A review of the literature and summary of the study results. Champaign-Urbana, IL: University of Illinois Graduate School of Library Science. Occasional papers No. 131. Library of Congress. Cataloging Policy and Support Office. (1996) Library of Congress Subject Headings. 19th ed. Washington, DC: Cataloging Distribution Service, Library of Congress. Library of Congress. Office for Subject Cataloging Policy. (1991- ) Subject cataloging manual. Subject headings. 4th ed. Washington, DC: Cataloging Distribution Service, Library of Congress. Liddy, E.D., Jorgensen, C.L., Sibert, E.E., & Yu, E.S. (1993) A sublangauge approach to natural language processing for an expert system. Information Processing & Management, 29, 633-645. Lilley, O.L. (1954) Evaluation of the subject catalog. American Documentation, 5, 41-60. Losee, R.M., & Haas, S.W. (1995) Sublanguage terms: Dictionaries, usage, and automatic classification. Journal of the American Society for Information Science, 46, 519-529. Luhn, H.P. (1957) A statistical approach to mechanized encoding and searching of literary information. IBM Journal of Research and Development, 1, 309-317. Lynch, C., & Garcia-Molina, H. (1995)Interoperability, scaling, and the digital libraries research agenda: A report on the May 18-19, 1995 IITA Digital Libraries Workshop, August 22, 1995. Online: http://www-diglib.stanford.edu/diglib/pub/reports/iita-dlw/main.html. Lynch, M.J. (1978) Reference interviews in public libraries. Library Quarterly, 48, 119-142. Markey, K. (1984a) Interindexer consistency tests: A literature review and report of a test of consistency in indexing visual materials. Library & Information Science Research, 6, 155-177. Markey, K. (1984b) Subject searching in library catalogs: Before and after the introduction of online catalogs. Dublin, OH: OCLC Online Computer Library Center. Meadows, A.J. (1974) Communication in science. London: Butterworths. Molto, M. (1993) Improving full text search performance through textual analysis. Information Processing & Management, 29, 615-632. Merton, R.K. (1973) The sociology of science: Theoretical and empirical investigations. Chicago: University of Chicago Press. Morton, H.C., & Price, A.J. (1986) The ACLS survey: Views on publications, computers, libraries. Scholarly Communication, 5, 1-16. Nelson, M.J. (1988) Correlation of term usage and term indexing frequencies. Information Processing & Management, 24, 541-547. Nelson, M.J., & Tague, J.M. (1985) Split size-rank models for the distribution of index terms. Journal of the American Society for Information Science, 36, 283-296. Newport, E.L., & Bellugi, U. (1978) Linguistic expression of category levels in a visual-gestural language: A flower is a flower is a flower. In E. Rosch, & B.B. Lloyd (Eds.), Cognition and categorization (pp. 49-71), Hillsdale, NJ: Lawrence Erlbaum. O’Connor, B.C. (1996) Explorations in indexing and abstracting. Englewood, CO: Libraries Unlimited. Pejtersen, A.M. (1994) A framework for indexing and representation of information based on work domain analysis: A fiction classification example. In H. Albrechtsen, & S. Oernager (Eds.), Knowledge organization and quality management (pp. 161-172), Frankfurt am Main: Indeks Verlag. Peterson, T., director. (1994) Art & architecture thesaurus. 2nd ed. New York: Oxford. Pinker, Steven. (1994) The language instinct. New York: HarperPerennial. Qiu, L. (1990). An empirical examination of the existing models for Bradford’s Law. Information Processing & Management, 26, 655-672. Ranganathan, S.R. (1963) Colon classification: Basic classification. 6th ed., New York: Asia Pub. House. Raven, P.H.; Berlin, B.; & Breedlove, D.E. (1971) The origins of taxonomy. Science, 174, 1210-1213. Resnikoff, H.L., & Dolby, J.L. (1972) Access: A study of information storage and retrieval with emphasis on library information systems. Washington, DC: U.S. Dept. of Health, Education, and Welfare, Office of Education, Bureau of Research. ERIC No. ED 060 921. Rosch, E.; Mervis, C.B.; Gray, W.D.; Johnson, D.M.; and Boyes-Braem, P. (1976) Basic objects in natural categories. Cognitive Psychology, 8, 382-439. Rosch, E. (1978) Principles of categorization. In E. Rosch, & B.B. Lloyd (Eds.), Cognition and categorization (pp. 27-48), Hillsdale, NJ: Lawrence Erlbaum. Rousseau, R. (1994) Bradford curves. Information Processing & Management, 30, 267-277. Rousseau, R. (1996) Personal communication. Rowley, J. (1992) Organizing knowledge: An introduction to information retrieval. 2nd. ed. Brookfield, VT: Ashgate. Saracevic, T., & Kantor, P. (1988) A study of information seeking and retrieving. III. Searchers, searches, and overlap. Journal of the American Society for Information Science, 39, 197-216. Schatz, B.R.; Johnson, E.H.; Cochrane, P.A.; & Chen, H. (1996) Interactive term suggestion for users of digital libraries: Using subject thesauri and co-occurrence lists for information retrieval. In Proceedings of the 1st ACM International Conference on Digital Libraries. (pp. 126-133) New York: Association for Computing Machinery. Siegfried, S.; Bates, M.J.; & Wilde, D.N. (1993) A profile of end-user searching behavior by humanities scholars: The Getty Online Searching Project report no. 2. Journal of the American Society for Information Science, 44, 273-291. Soergel, D. (1985) Organizing information: Principles of database and retrieval systems. Orlando, FL: Academic Press. Solomon, P. (1993) Children’s information retrieval behavior: A case analysis of an OPAC. Journal of the American Society for Information Science, 44, 245-264. Stevens, M. E. (1965) Automatic indexing: A state-of-the-art report. Washington, D.C.: U.S.G.P.O. National Bureau of Standards Monograph 91. Stewart, J.A. (1994) The Poisson-lognormal model for bibliometric/scientometric distributions. Information Processing & Management, 30, 239-251. Swift, D.F., Winn, V.A., & Bramer, D.A. (1979) A sociological approach to the design of information systems. Journal of the American Society for Information Science, 30, 215-223. Tibbo, H.R. (1994). Indexing for the humanities. Journal of the American Society for Information Science, 45, 607-619. Union list of artist names. (1994) {computer file} Version 1.0. New York: G.K. Hall/Macmillan. Vickery, B.C. (1968) Faceted classification: A guide to construction and use of special schemes. London: Aslib. Weinberg, B.H. (1988) Why indexing fails the researcher. The Indexer, 16, 3-6. White, H.D.; Bates, M.J.; & Wilson, P. (1992) For information specialists: Interpretations of reference and bibliographic work. Norwood, NJ: Ablex. Wiberley, S.E. (1983) Subject access in the humanities and the precision of the humanist’s vocabulary. Library Quarterly, 53, 420-433. Wiberley, S.E. (1988) Names in space and time: The indexing vocabulary of the humanities. Library Quarterly, 58, 1-28. Wiberley, S.E.; Daugherty, R.A.; & Danowski, J.A. (1990) User persistence in scanning postings of a computer-driven information system: LCS. Library and Information Science Research, 12, 341-353. Wiberley, S.E.; Daugherty, R.A.; & Danowski, J.A. (1995) User persistence in displaying online catalog postings: LUIS. Library Resources & Technical Services, 39, 247-264. Wilson, P. (1968) Two kinds of power: An essay on bibliographical control. Berkeley, CA: University of California Press. Zipf, G.K. (1949) Human behavior and the principle of least effort: An introduction to human ecology. Cambridge, MA: Addison-Wesley. |